
The Compression Axiom
For a decade, the field has debated the "Robustness vs. Accuracy" trade-off: the belief that one must sacrifice model performance to make it safe. We reject this premise.
Our research posits that adversarial vulnerability is not a stochastic failure of the learning process ("bugs"), but a deterministic artifact of hyper-efficient compression, known as Superposition.
To achieve high-efficiency inference, neural networks pack features into dimensions (where ). The so-called "attacks" are simply the mathematical residue of these overlapping feature vectors. To remove the vulnerability via traditional means (like adversarial training) is to cripple the model's capacity to compress information.
Foundational Physics: The Three Axioms
The Oblique-Guard architecture rests on three axiomatic definitions of neural computation, operationalizing the "Linear Representation Hypothesis" as a strict encoding standard.
I. Linear Semantic Alignment (LSA)
We treat latent activations not as amorphous tensors, but as discrete superpositions of semantic variables. A change in a concept (e.g., "Cat" to "Dog") manifests as a precise linear translation in activation space.
II. Hyper-Dimensional Feature Interleaving (HDFI)
The engine utilizes HDFI to maximize entropic efficiency. This state is defined by:
- Overcompleteness: The feature basis exceeds the channel width ().
- Non-Orthogonality: Feature vectors exhibit non-zero cosine similarity ().
III. The Adversarial Manifold
We redefine "Adversarial Attacks" as Interference Exploits. An adversarial perturbation is a calculated input vector designed to maximize the Deterministic Interference term, pushing an activation across a decision threshold without semantic justification.
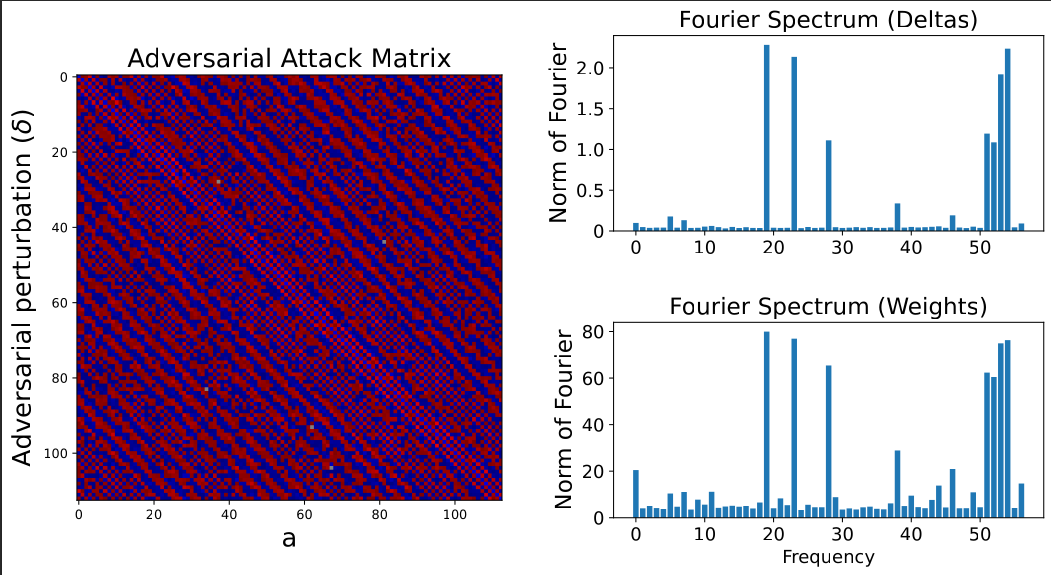
Figure 2: The Interference Highway. The adversary is not "tricking" the model; they are traversing a predictable path built by the model's own compression efficiency.
The "Kill Vector" Derivation
Our synthetic diagnostics confirm that adversaries do not inject random noise. Instead, they solve for specific Interference Normals.
We derived the exact form of the optimal adversarial perturbation () in a linear superposition regime:
This equation proves that the attack is strictly proportional to the interference between the target feature and the current feature . If the model's geometry is known, the attack is calculable, and therefore filterable.
Experimental Validation
We deployed this architecture on a standard Vision Transformer (ViT) chassis calibrated on CIFAR-10, utilizing a custom Interference Compression Module (ICM) to force superposition.
1. The Law of Inverse Robustness
Our results confirm a strict scaling law: As the bottleneck dimension decreases (increasing superposition pressure), the Normalized Robust Accuracy collapses. Denser packing reduces the margin for error, requiring smaller perturbations to bridge the distance between features.
2. Geometric Synchronization (Transferability)
Perhaps most critically, we found that input correlations constrain the lattice geometry.
- Uncorrelated Inputs: Result in stochastic, unique lattices.
- Correlated Inputs (Real World): Result in Deterministic Lattices. Independent models converge to nearly identical geometric arrangements.
This explains Attack Transferability: An attack generated on Model A succeeds on Model B because they share the same "Interference Highways."
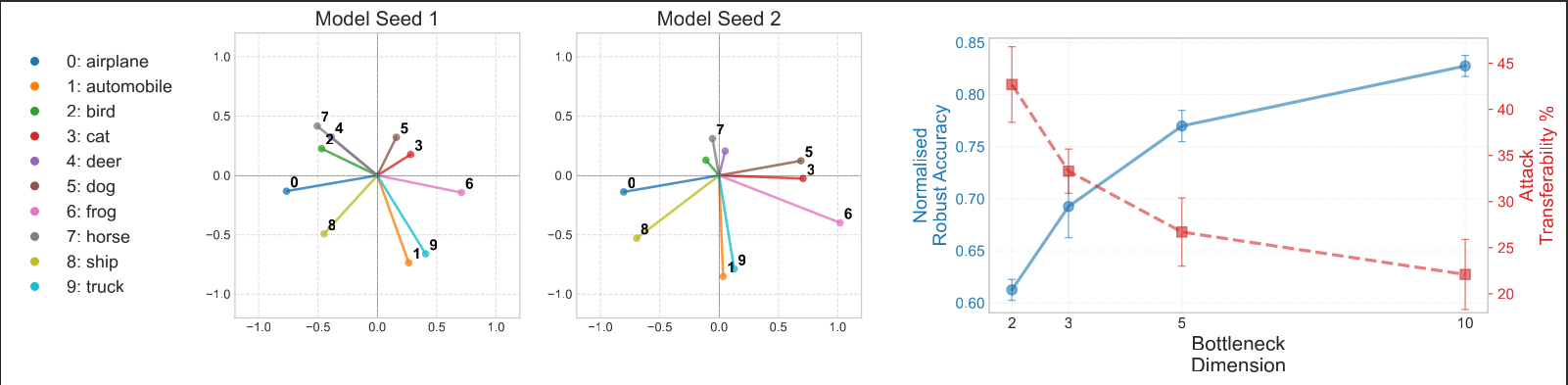
Figure 3: Geometric Convergence. Models trained on correlated data form identical interference patterns.
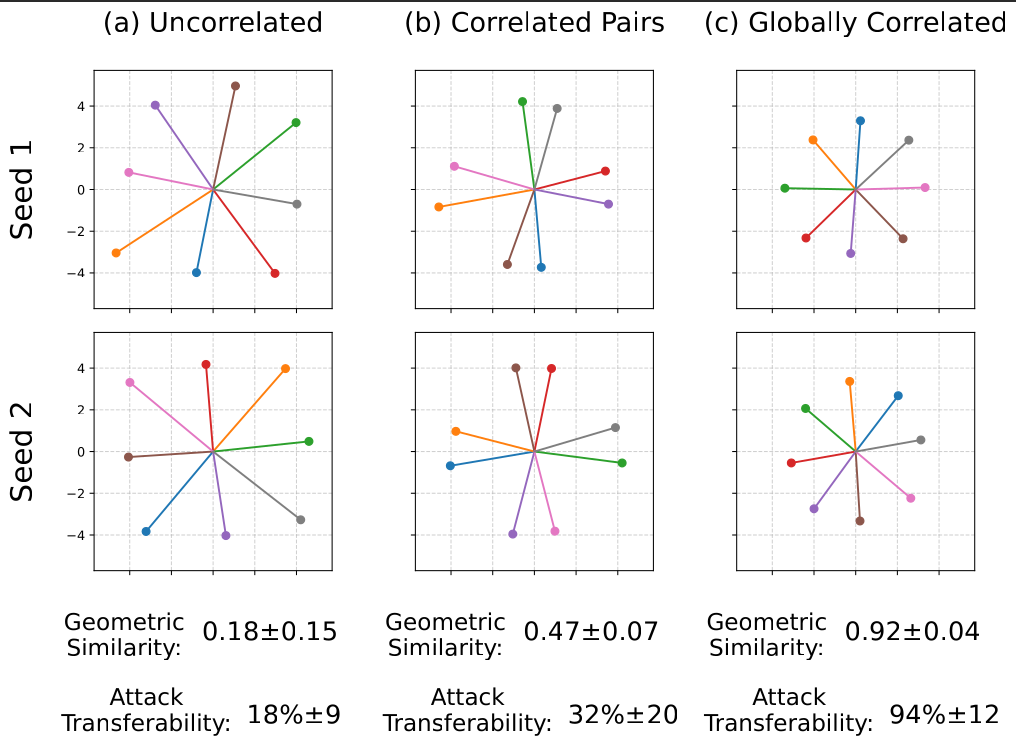
Figure 4: Transferability of Attacks. As compression increases, shared vulnerability spikes to near-unity.
The Solution: Oblique-Guard
Instead of retraining the model to be "robust" (and less capable), we introduce the Oblique-Guard Layer.
This module treats the latent space as a known Interference Lattice. We map specific vector combinations where superposed features destructively interfere. Any input gradient attempting to traverse these specific high-interference corridors is flagged as an "Algorithmic Exploit" and zeroed out before activation.
By identifying inputs that align perfectly with our internal interference geometry, we effectively convert "Adversarial Vulnerability" from a liability into a unique digital signature of the attack itself.