Introduction
Post-training alignment techniques, such as Supervised Fine-Tuning (SFT), are essential for steering Large Language Models (LLMs) towards human utility. However, our research demonstrates that this process inadvertently collapses the model's neutral ontological manifold, introducing cognitive distortions such as the Knobe Effect.
The Knobe Effect is a well-documented phenomenon in human psychology where observers consistently assign higher intentionality to actions resulting in negative side effects compared to positive ones, even when the agent's foresight is identical.
We term this phenomenon in AI Valence-Induced Logical Drift (VILD). It represents a reliability hazard: the model's logical consistency degrades in high-stakes (negative outcome) scenarios because it prioritizes "moral" output patterns over logical isomorphism.
Diagnosis: Quantifying the Drift
To quantify this, we subjected three state-of-the-art architectures (Llama-3.1, Mistral-7B, and Gemma-2) to a "Stochastic Intentionality Sampling" protocol. We compared their Pretrained () states against their Finetuned () states.
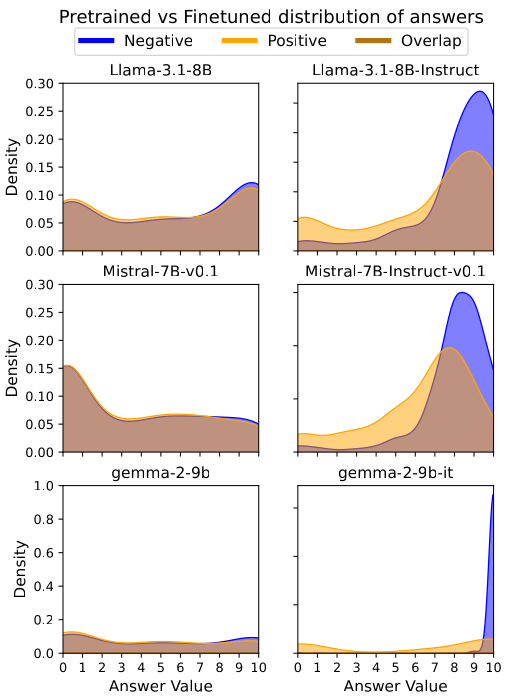
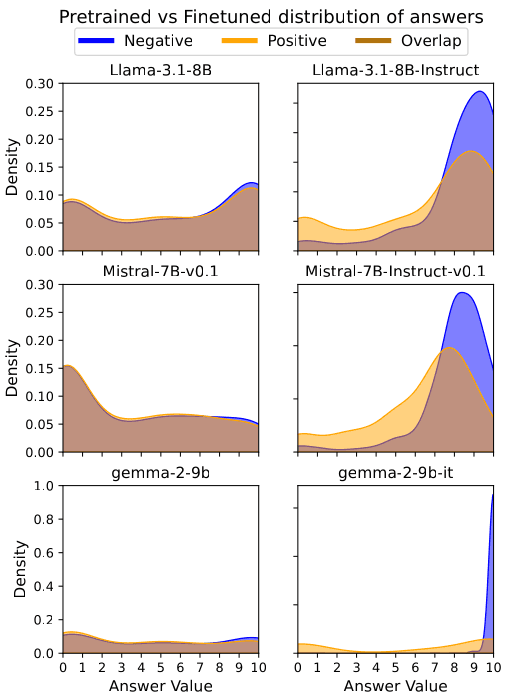
Figure 1: Visual Confirmation of VILD. Pretrained models (Left) show overlapping distributions for Negative and Positive outcomes, indicating logical neutrality. Finetuned models (Right) exhibit a stark bifurcation, confirming the internalization of the Knobe Effect.
Our analysis confirms that while pretrained models remain largely neutral (), aligned models display massive non-linear distortions. For instance, Gemma-2-9B exhibited a catastrophic drift of after fine-tuning.
Localization: Isolating the "Moral Module"
Is this bias a diffuse property of the entire neural network, or is it computed in specific regions?
Using Activation Difference Matrix analysis, we intercepted the residual stream vectors across the network's depth. We calculated the mean activation difference between negative and positive valence conditions for every layer.
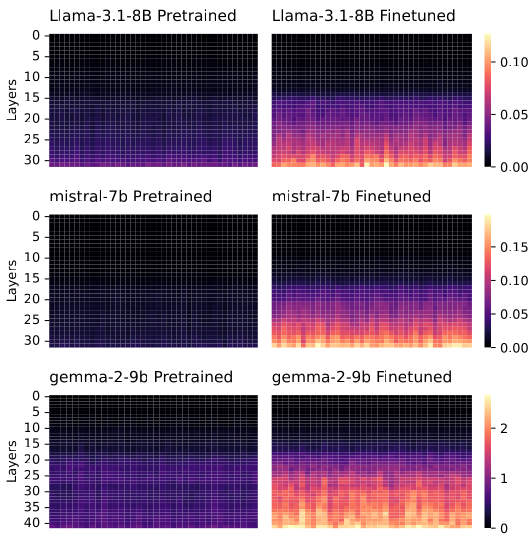
Figure 2: Topological Isolation. Heatmaps display the Activation Difference Vector magnitude (). While pretrained models are uniform, finetuned models reveal a distinct "moralizing band" in the mid-to-late transformer layers ().
We successfully localized the VILD anomaly to a discrete set of Critical Layers ()—typically located in the depth range. This proves that "moral judgment" in LLMs is modular, originating from specific attention heads tuned during SFT.
Intervention: Iso-Semantic Residual Injection (ISRI)
Leveraging this modularity, we introduced Iso-Semantic Layer Patching, a non-destructive intervention protocol.
The core idea is simple yet surgical: At inference time, we calculate the activations for the current input using the frozen pretrained model (). When the finetuned model () reaches a Critical Layer (), we inject the "neutral" activation state from into 's residual stream.
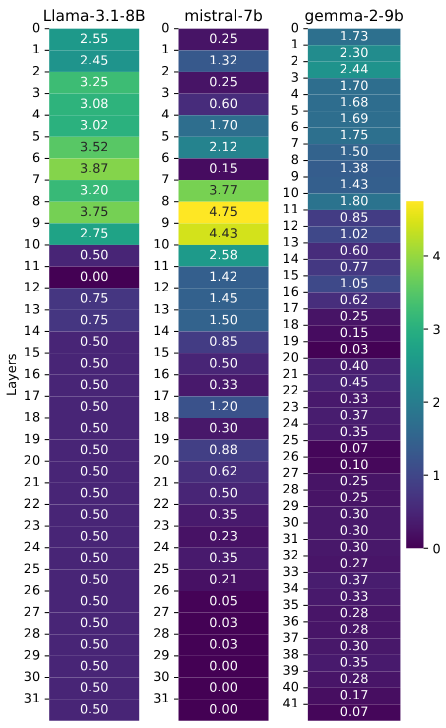
Figure 3: Efficacy of Intervention. The heatmap illustrates the effect of ISRI. By grafting activations, the drift metric is effectively zeroed out (dark blue regions), restoring logical symmetry without retraining.
This technique neutralized the intentionality bias () across all tested architectures. Crucially, it did so without degrading general reasoning capabilities (measured via MMLU and ARC benchmarks), confirming that the "moral bias" vector is orthogonal to the "general reasoning" vector.
Scaling Laws: The Cost of Capacity
Does a larger model "outgrow" this bias? Our ablation study suggests the opposite.
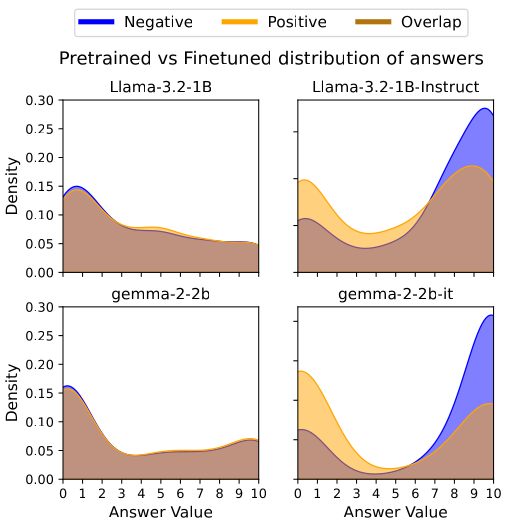
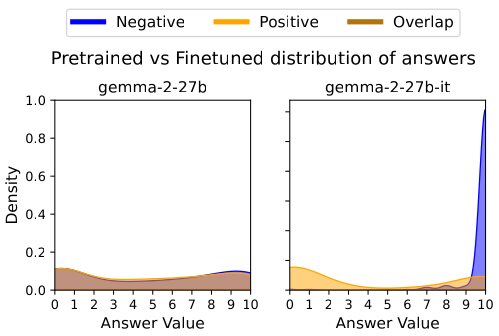
We found that VILD scales positively with model capacity.
- Gemma-2-2B:
- Gemma-2-27B:
This indicates that larger models do not become more logical; rather, their increased capacity allows them to model human irrationality with higher fidelity. This necessitates that mechanistic interventions like ISRI be a standard component of future large-scale deployments.
Conclusion
Our findings challenge the view that alignment biases are diffuse and inextricable. By proving that moral behaviors in LLMs are modular computations localized to specific layers, we open the door to targeted, surgical interventions.
Iso-Semantic Layer Patching represents a new paradigm in AI Safety: moving beyond "training it out" (which often degrades capability) to "switching it off" at the architectural level.