
1. Introduction
Modern Optical Character Recognition (OCR) has evolved far beyond simple text extraction. Today's applications require handling complex document parsing, information extraction (IE), and text-centric visual question answering (VQA).
Traditional OCR systems typically rely on cascaded pipelines—stringing together separate modules for text detection, recognition, and layout analysis. While modular, these pipelines suffer from error propagation, where a failure in detection cascades through the entire system, and high maintenance complexity.
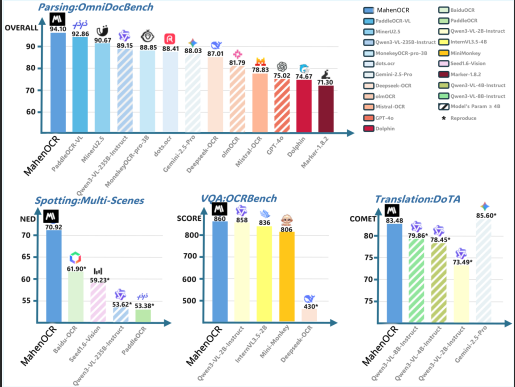
Figure 1: Performance Comparison. MahenOCR (1B) achieves competitive or superior performance across multiple benchmarks compared to traditional pipelines and larger VLMs.
2. Architecture
MahenOCR represents a shift to a pure end-to-end Vision-Language Model (VLM) architecture. By unifying diverse tasks into a single framework, we eliminate the need for intermediate pre-processing modules like layout analysis.
MahenOCR achieves high efficiency with a compact 1B parameter footprint, making it suitable for edge and low-latency applications. The architecture consists of three core components:
- Native Resolution Visual Encoder: Built on SigLIP-v2-400M, using an adaptive patching mechanism to preserve aspect ratio.
- Adaptive MLP Connector: A learnable bridge compressing visual tokens to reduce redundancy.
- Lightweight Language Model: Based on the Metanthropic-0.5B model, utilizing XD-RoPE for robust spatial reasoning.

Figure 2: Model Architecture. The end-to-end flow from high-resolution visual encoding to auto-regressive text generation.
3. Methodology & Pipeline
Our approach streamlines the traditional multi-stage pipeline into a unified differentiable flow. This allows the model to leverage the reasoning capabilities of Large Language Models (LLMs) for superior performance on cognitive-intensive tasks.

Figure 3: Pipeline Comparison. Contrasting the MahenOCR end-to-end approach with traditional cascaded OCR systems.
Data Pipeline & RLVR
A key innovation is the application of Reinforcement Learning with Verifiable Rewards (RLVR). We employ Group Relative Policy Optimization (GRPO) to fine-tune the model on objective metrics:
- Spotting: Intersection over Union (IoU) rewards.
- Parsing: Structural integrity rewards (HTML/LaTeX validity).

Figure 4: Data Construction & Training Pipeline. From raw document sourcing to RL-based fine-tuning.
4. Unified Capabilities
MahenOCR consolidates a wide range of capabilities into a single model, demonstrating robust performance across diverse document intelligence tasks.
4.1 Text Spotting
Jointly detecting and recognizing text with precise coordinate outputs.

4.2 Document Parsing
End-to-end conversion of documents into structured Markdown, with tables in HTML and formulas in LaTeX.

4.3 Translation & Information Extraction
Direct image-to-text translation and structured JSON extraction from receipts and IDs.

5. Conclusion
MahenOCR demonstrates that a well-designed, data-driven 1B parameter model can rival the performance of significantly larger models and commercial APIs. By combining a streamlined end-to-end architecture with targeted reinforcement learning, we provide a robust, open-source foundation for the next generation of industrial OCR applications.