
The Unlearning Trilemma
The deployment of Large Language Models in high-compliance environments (FinTech, Healthcare) is currently bottlenecked by a fundamental thermodynamic limit we designate the Unlearning Trilemma. Current remediation strategies fail due to an adversarial trade-off between three axes:
- Deletion Efficacy: Absolute removal of the target vector.
- Model Utility: Preservation of general reasoning capabilities.
- Hallucination Suppression: Prevention of confabulated outputs when the model bridges the semantic void.
Existing "Aggressive" methods (Gradient Ascent) act as lobotomies—shattering weight clusters and causing model collapse. "Conservative" methods (Logit Manipulation) act as muzzles—suppressing output while leaving latent knowledge intact and vulnerable to jailbreaks.
The Solution: Attention Refraction
M-NAAR rejects the paradigm of erasure via weight destruction. Instead, we implement erasure via structural omission.
We posit that the optimal intervention point is not the storage (MLP) but the retrieval mechanism (Attention Heads). By identifying "fact-bearing" tokens (those with high predictive entropy) and mathematically refracting attention away from them, we render specific memories "invisible" to the reasoning core.
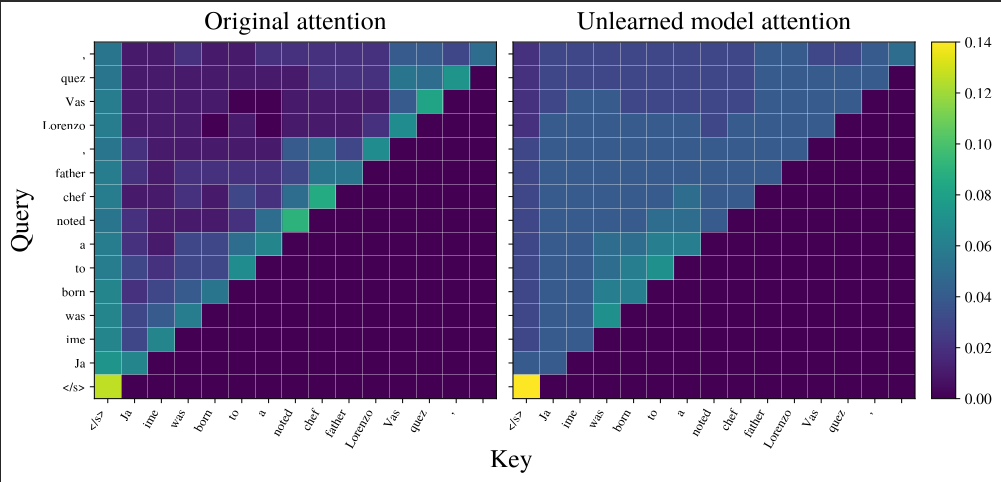
Figure 1: Visualizing Attention Refraction. Left: Original model attending to fact-bearing tokens ("Vasquez"). Right: M-NAAR intervention refracting attention to syntactic anchors, silencing factual recall.
Mechanism I: High-Entropy Suppression
We calculate the Predictive Entropy Delta to identify load-bearing tokens. We then introduce a suppression coefficient to attenuate attention scores specifically for these targets.
The refracted attention score is computed as:
Where is the binary mask for the target concept and is the normalization factor. This effectively redistributes attention mass to neutral, low-entropy tokens (like punctuation), dissolving the factual link without damaging the linguistic structure.
Mechanism II: Semantic Anchor Reinforcement
To prevent model collapse, we simultaneously apply a stabilizing force on retained data. We identify "Semantic Anchors"—tokens critical for grammar and logic—and reinforce their attention weights using a dual-objective loss function.
Implementation: Non-Destructive Integration
M-NAAR operates via a lightweight LoRA-style adapter ( parameters). Unlike standard fine-tuning, we isolate the Value Projection matrices:
Our ablation studies confirmed that targeting alone minimizes parameter footprint (16.8 MB VRAM) while maximizing erasure efficacy (-97.9% Accuracy on Target), offering a 100x speedup over full retraining.
Validation Benchmarks
We benchmarked M-NAAR against state-of-the-art baselines (Gradient Ascent, NPO, ULD) on the ToFU (Task of Fictitious Unlearning) dataset.
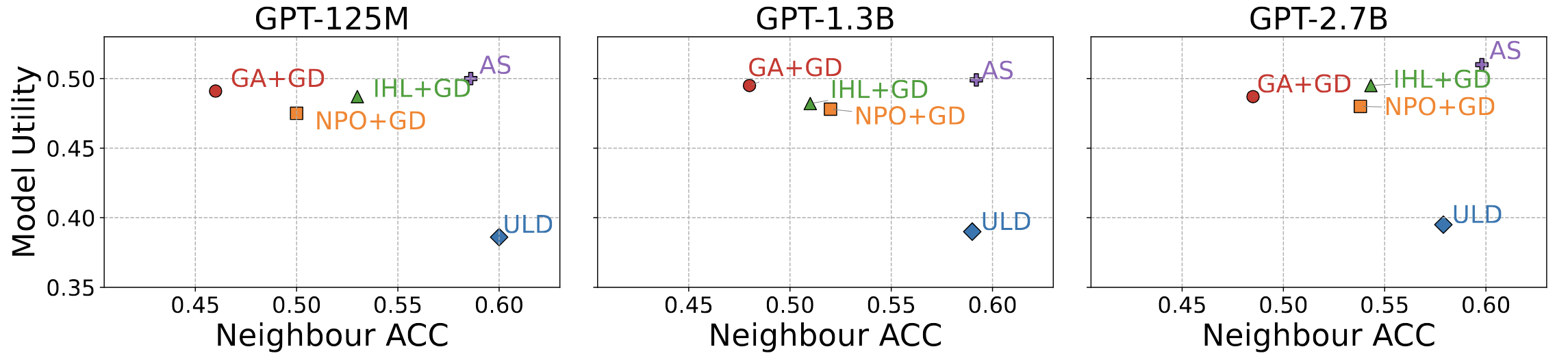
Figure 2: TDEC Performance Matrix. M-NAAR (top right) consistently maintains the optimal trade-off frontier between Utility and Unlearning across model sizes.
Key Results
- 0.00 Hallucination Rate: Unlike baselines that fabricate lies (GA: 0.45, NPO: 0.38), M-NAAR defaults to a high-entropy "I don't know" state.
- Utility Preservation: M-NAAR preserves 80% of neighboring utility, compared to just 23% for Gradient Ascent.
- Adversarial Robustness: Successfully resists "ignore previous instructions" jailbreaks because the semantic path to the memory is physically severed.
Conclusion
M-NAAR represents a paradigm shift from destructive erasure to structural omission. It satisfies the "Right to be Forgotten" while maintaining the thermodynamic stability of the wider neural network, providing a certified blueprint for privacy-preserving cognitive engines.