
Large Language Models (LLMs) have demonstrated a profound capacity for In-Context Learning (ICL), yet the internal causal mechanisms that drive these emergent behaviors remain a "black box" of high-dimensional entanglement.
At Metanthropic, we believe that bridging the gap between linguistic pattern-matching and objective reasoning requires a mechanistic deconstruction of how models internalize structural priors. Physics-based dynamics offer a rigorous, experimentally controllable alternative to abstract symbolic benchmarks, serving as a critical testbed for evaluating the transition from statistical extrapolation to grounded world-modeling.
In this work, we conduct a mechanistic audit of the LLM residual stream during physics-forecasting tasks. Our findings suggest that models do not merely predict the next numerical token; they actively construct internal features that correlate with fundamental physical invariants.
The Metanthropic Mechanistic Audit
To move beyond surface-level evaluation, we established a "Physical Laboratory" within the model's activation space. We tasked frontier models with forecasting dynamical systems—ranging from stable 1D oscillators to chaotic 3D coupled pendulums—while simultaneously auditing their internal states.
Our methodology relies on Sparse Autoencoders (SAEs) to disentangle the residual stream. This allows us to map the dense, noisy activity of the network into interpretable, monosemantic features.
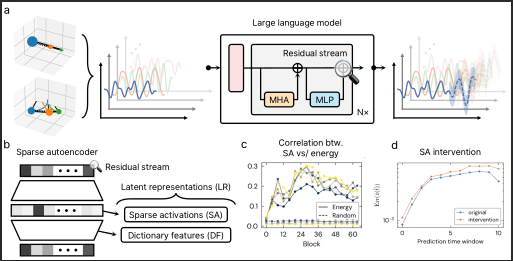
Figure 1: The Metanthropic Mechanistic Audit. (a) Predictive Mapping of residual streams. (b) SAE-based Latent Disentanglement. (c) Structural Validation against physical invariants.
Key Finding: The "Warm-Up" of Intelligence
We observed a clear phase transition in forecasting capability. Forecasting precision is not static; it is a direct function of context depth. This suggests a latent "warm-up" phase where the model incrementally builds an in-context world model before it can accurately simulate dynamics.
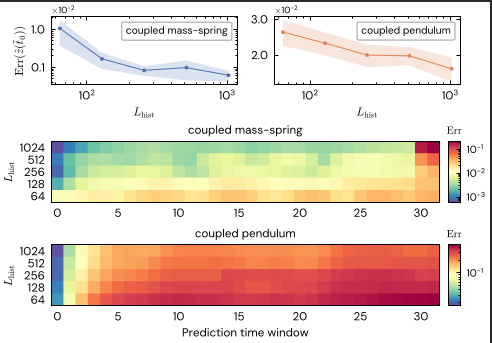
Figure 2: Intelligence Scales with Context. We observe that forecasting error decreases monotonically as the model accumulates more history (L-hist), confirming active calibration.
Spontaneous Physics Engines
Perhaps our most significant finding is that LLMs appear to reinvent physics from scratch. By analyzing the features extracted by our SAEs, we identified specific latent circuits that track Energy—both kinetic and potential.
These are not heuristics explicitly taught to the model; they are emergent structures that the model synthesizes to compress the task data. The model "learns" that Energy is a conserved quantity because it is the most efficient way to predict the next token in a physical system.
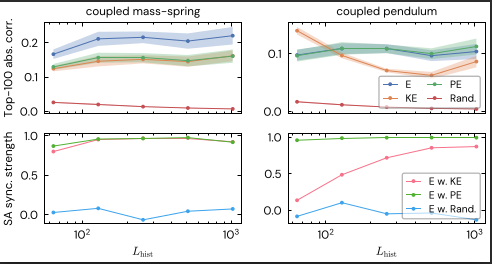
Figure 3: Latent Energy Circuits. Correlation analysis reveals internal features that track the system's total energy, intensifying as context depth increases.
The Fragility of Reasoning
To verify that these features were causal—and not just correlative—we performed ablation studies (a "Doubt Switch"). When we dampened these specific energy-tracking circuits, the model's predictive accuracy collapsed catastrophically.
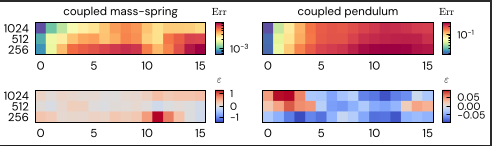
Figure 4: Causal Necessity. Ablating the identified energy circuits results in a collapse of predictive capability, confirming their functional necessity.
The Metanthropic Horizon
This work establishes a new precedent for our mission: uncovering the latent reasoning circuits that allow AI to move beyond text and into the structural reality of the physical world.
By proving that LLMs can spontaneously encode objective physical concepts, we move one step closer to systems that are not just fluent, but grounded. If we can audit the physics of intelligence, we can engineer systems where safety is not a guardrail, but a fundamental law of their operation.