Introduction
The current frontier of AI is defined by "reasoning models"—systems that can "think" before they speak, dynamically allocating compute to solve complex problems. However, these capabilities have largely been locked behind proprietary APIs.
Today, we release Arvi 20B, an open-weight reasoning model designed to bring these agentic capabilities to everyone. Built as a Mixture-of-Experts (MoE) transformer, Arvi 20B offers a powerful balance of performance and efficiency: while it has 20.9B total parameters, it uses only 3.6B active parameters per token.
This allows it to run on consumer-grade hardware (requiring as little as 16GB VRAM with quantization) while delivering performance that competes with models like OpenAI's o3-mini and our own o4-mini.
Architecture: Efficiency by Design
Arvi 20B is built on a sparse Mixture-of-Experts (MoE) architecture. Unlike dense models that activate every neuron for every token, Arvi selectively activates only the most relevant "experts."
- Total Parameters: 20.91 Billion
- Active Parameters: 3.61 Billion (per forward pass)
- Experts: 32 Experts (Top-4 routing)
- Context Window: 131,072 tokens (via YaRN)
To further democratize access, we post-trained the model using MXFP4 quantization, compressing the MoE weights (which make up 90%+ of the model) to just 4.25 bits. This drastic reduction in memory footprint enables high-end reasoning on single-GPU setups.
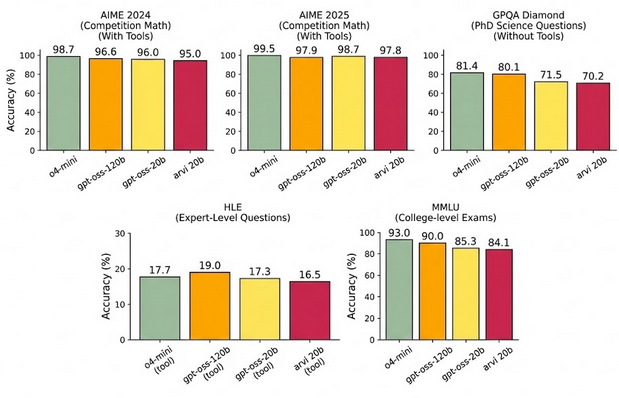
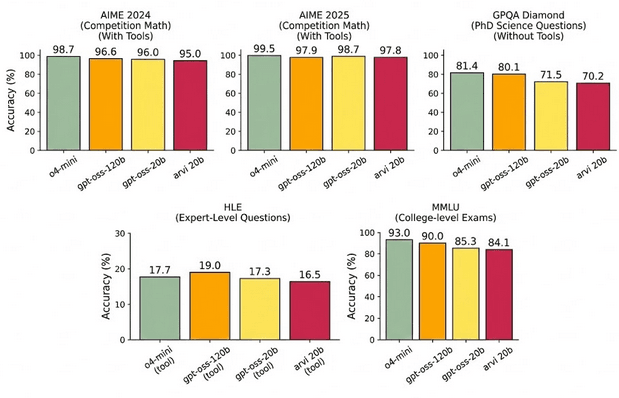
Figure 1: Main Capabilities. Comparison of Arvi 20B (High Reasoning) against closed frontier models. It surpasses o3-mini on AIME and approaches o4-mini accuracy.
Variable Effort Reasoning
A key feature of Arvi is its ability to adjust its "thinking" depth. We trained the model to support three distinct reasoning levels—Low, Medium, and High—configured via the system prompt.
As shown in the scaling laws below, increasing the reasoning level (and thus the length of the Chain-of-Thought) yields log-linear improvements in accuracy across hard tasks like AIME (Math) and GPQA (Graduate-Level Science).
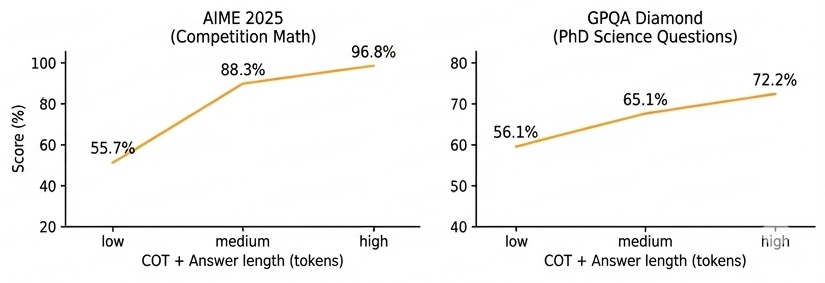
Figure 2: Test-Time Scaling. Accuracy increases smoothly as the model allocates more tokens to its internal Chain-of-Thought (CoT).
Agentic Capabilities & The Harmony Format
Reasoning is only half the equation; action is the other. Arvi 20B is trained using our custom Harmony Chat Format, which structures interactions into a hierarchy: System > Developer > User > Assistant > Tool.
This format allows the model to:
- Interleave Thoughts and Actions: The model can "think" about a problem, decide to call a tool (like a Python interpreter or Web Search), analyze the result, and then continue reasoning.
- Strict Instruction Adherence: By distinguishing between System and Developer messages, Arvi follows a robust priority hierarchy, reducing the risk of prompt injections.
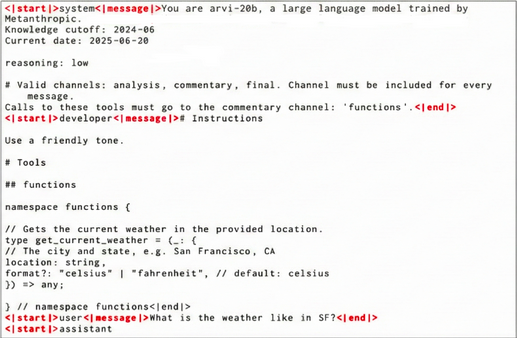
Figure 3: The Harmony Format. An example showing the model interleaving Chain-of-Thought (CoT) with tool execution.
Coding and Tool Use Results
These architectural choices translate to exceptional performance in agentic domains. On Codeforces (competitive programming) and SWE-bench Verified (real-world software engineering), Arvi 20B performs competitively with significantly larger models.
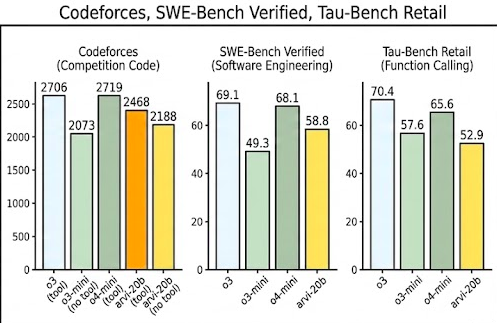
Figure 4: Coding & Agents. Arvi 20B demonstrates strong developer capabilities, excelling in environment-based coding tasks.
Safety & Health Intelligence
Open weights present unique safety challenges. We conducted extensive "red-teaming" and adversarial fine-tuning to ensure Arvi 20B does not pose significant risks in critical areas like Cybersecurity or Biorisk.
Interestingly, the model shows remarkable utility in positive domains. On HealthBench, a dataset evaluating realistic health conversations, Arvi 20B (High Reasoning) outperforms GPT-4o and o1-preview, offering a powerful tool for global health equity where low-cost, offline inference is crucial.
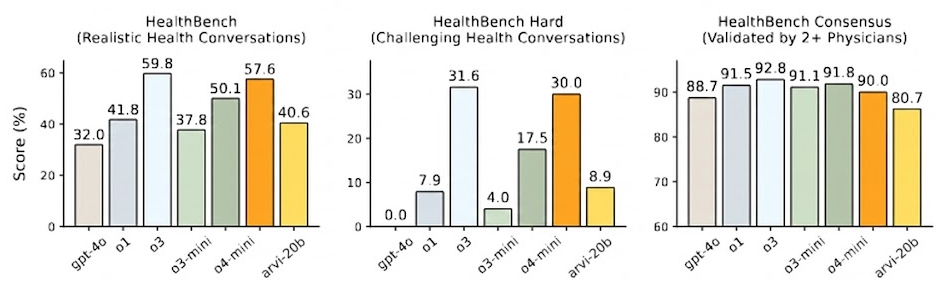
Figure 5: Health Intelligence. Arvi 20B delivers state-of-the-art performance on medical reasoning tasks compared to similarly sized models.
Conclusion
Arvi 20B represents a shift in what open-source models can achieve. By combining the efficiency of Mixture-of-Experts with the cognitive depth of test-time compute, we are providing developers with a model that is not just "smart for its size," but genuinely capable of solving complex, multi-step problems.
We invite the community to explore the weights on HuggingFace and begin building the next generation of agentic applications.